publications
publications in reversed chronological order. generated by jekyll-scholar.
2025
-
 Train your robot in AR: insights and challenges for humans and robots in continual teaching and learningAnna Belardinelli, Chao Wang, Daniel Tanneberg, Stephan Hasler, and Michael GiengerFrontiers in Robotics and AI, 2025
Train your robot in AR: insights and challenges for humans and robots in continual teaching and learningAnna Belardinelli, Chao Wang, Daniel Tanneberg, Stephan Hasler, and Michael GiengerFrontiers in Robotics and AI, 2025Supportive robots that can be deployed in our homes will need to be understandable, operable, and teachable by non-expert users. This calls for an intuitive Human-Robot Interaction approach that is also safe and sustainable in the long term. Still, few studies have looked at interactive task learning in repeated, unscripted interactions within loosely supervised settings. In such cases the robot should incrementally learn from the user and consequentially expand its knowledge and abilities, a feature which presents the challenge of designing robots that interact and learn in real time. Here, we present a robotic system capable of continual learning from interaction, generalizing learned skills, and planning task execution based on the received training. We were interested in how interacting with such a system would impact the user experience and understanding. In an exploratory study, we assessed such dynamics with participants free to teach the robot simple tasks in Augmented Reality without supervision. Participants could access AR glasses spontaneously in a shared space and demonstrate physical skills in a virtual kitchen scene. A holographic robot gave feedback on its understanding and, after the demonstration, could ask questions to generalize the acquired task knowledge. The robot learned the semantic effects of the demonstrated actions and, upon request, could reproduce those on observed or novel objects through generalization. The results show that the users found the system engaging, understandable, and trustworthy, but with larger variance on the last two constructs. Participants who explored the scene more were able to expand the robot’s knowledge more effectively, and those who felt they understood the robot better were also more trusting toward it. No significant variation in the user experience or their teaching behavior was found across two interactions, yet the low return rate and free-form comments hint at critical lessons for interactive learning systems.
@article{belardinelli2025train, author = {Belardinelli, Anna and Wang, Chao and Tanneberg, Daniel and Hasler, Stephan and Gienger, Michael}, title = {Train your robot in AR: insights and challenges for humans and robots in continual teaching and learning}, journal = {Frontiers in Robotics and AI}, year = {2025}, } -
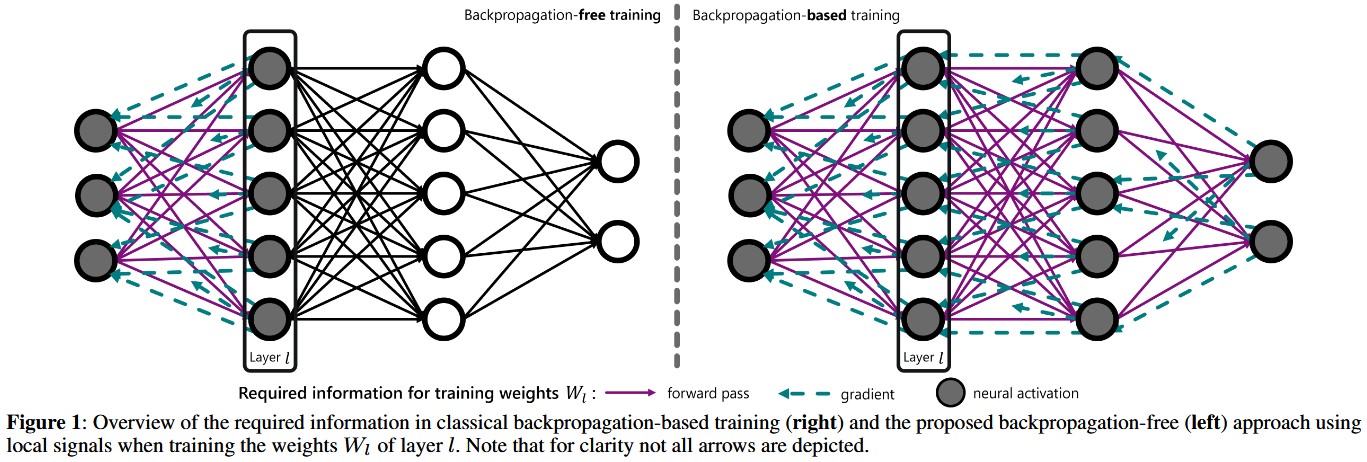 Local Pairwise Distance Matching for Backpropagation-Free Reinforcement LearningDaniel TannebergIn European Conference on Artificial Intelligence (ECAI), 2025
Local Pairwise Distance Matching for Backpropagation-Free Reinforcement LearningDaniel TannebergIn European Conference on Artificial Intelligence (ECAI), 2025Training neural networks with reinforcement learning (RL) typically relies on backpropagation (BP), necessitating storage of activations from the forward pass for subsequent backward updates. Furthermore, backpropagating error signals through multiple layers often leads to vanishing or exploding gradients, which can degrade learning performance and stability. We propose a novel approach that trains each layer of the neural network using local signals during the forward pass in RL settings. Our approach introduces local, layer-wise losses leveraging the principle of matching pairwise distances from multi-dimensional scaling, enhanced with optional reward-driven guidance. This method allows each hidden layer to be trained using local signals computed during forward propagation, thus eliminating the need for backward passes and storing intermediate activations. Our experiments, conducted with policy gradient methods across common RL benchmarks, demonstrate that this backpropagation-free method achieves competitive performance compared to their classical BP-based counterpart. Additionally, the proposed method enhances stability and consistency within and across runs, and improves performance especially in challenging environments.
@inproceedings{tanneberg2025local, author = {Tanneberg, Daniel}, title = {Local Pairwise Distance Matching for Backpropagation-Free Reinforcement Learning}, booktitle = {European Conference on Artificial Intelligence (ECAI)}, year = {2025}, } -
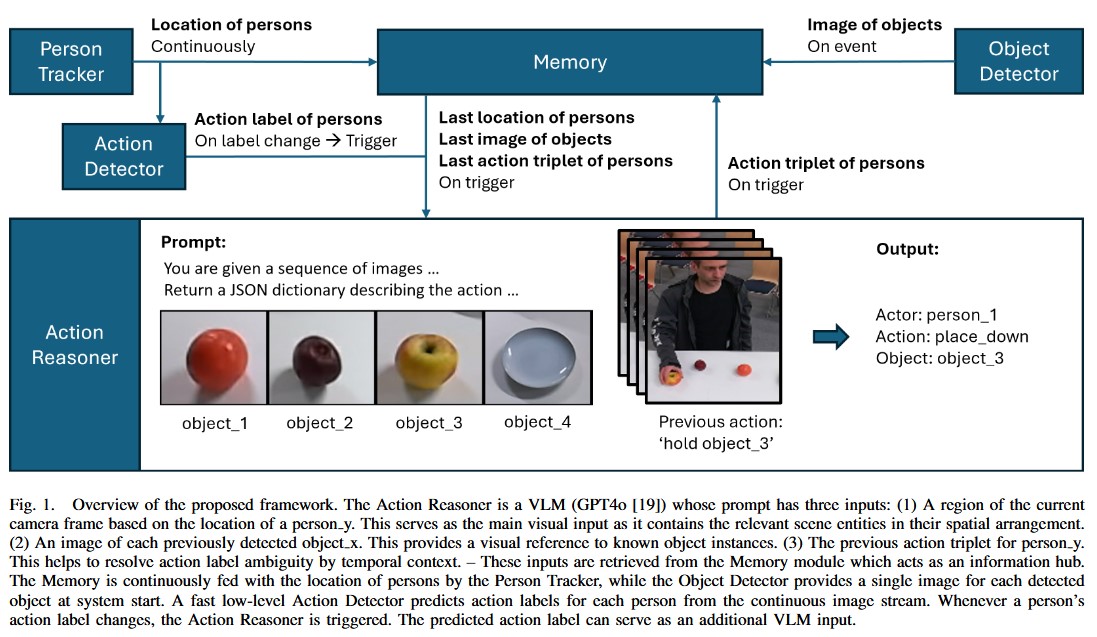 CARMA: Context-Aware Situational Grounding of Human-Robot Group Interactions by Combining Vision-Language Models with Object and Action RecognitionJoerg Deigmoeller, Stephan Hasler, Nakul Agarwal, Daniel Tanneberg, Anna Belardinelli, Reza Ghoddoosian, Chao Wang, Felix Ocker, Fan Zhang, Behzad Dariush, and othersarXiv preprint arXiv:2506.20373, 2025
CARMA: Context-Aware Situational Grounding of Human-Robot Group Interactions by Combining Vision-Language Models with Object and Action RecognitionJoerg Deigmoeller, Stephan Hasler, Nakul Agarwal, Daniel Tanneberg, Anna Belardinelli, Reza Ghoddoosian, Chao Wang, Felix Ocker, Fan Zhang, Behzad Dariush, and othersarXiv preprint arXiv:2506.20373, 2025We introduce CARMA, a system for situational grounding in human-robot group interactions. Effective collaboration in such group settings requires situational awareness based on a consistent representation of present persons and objects coupled with an episodic abstraction of events regarding actors and manipulated objects. This calls for a clear and consistent assignment of instances, ensuring that robots correctly recognize and track actors, objects, and their interactions over time. To achieve this, CARMA uniquely identifies physical instances of such entities in the real world and organizes them into grounded triplets of actors, objects, and actions. To validate our approach, we conducted three experiments, where multiple humans and a robot interact: collaborative pouring, handovers, and sorting. These scenarios allow the assessment of the system’s capabilities as to role distinction, multi-actor awareness, and consistent instance identification. Our experiments demonstrate that the system can reliably generate accurate actor-action-object triplets, providing a structured and robust foundation for applications requiring spatiotemporal reasoning and situated decision-making in collaborative settings.
@article{deigmoeller2025carma, title = {CARMA: Context-Aware Situational Grounding of Human-Robot Group Interactions by Combining Vision-Language Models with Object and Action Recognition}, author = {Deigmoeller, Joerg and Hasler, Stephan and Agarwal, Nakul and Tanneberg, Daniel and Belardinelli, Anna and Ghoddoosian, Reza and Wang, Chao and Ocker, Felix and Zhang, Fan and Dariush, Behzad and others}, journal = {arXiv preprint arXiv:2506.20373}, year = {2025}, } -
 Mirror Eyes: Explainable Human-Robot Interaction at a GlanceMatti Krüger, Daniel Tanneberg, Chao Wang, Stephan Hasler, and Michael GiengerIn IEEE International Conference on Robot and Human Interactive Communication (RO-MAN), 2025
Mirror Eyes: Explainable Human-Robot Interaction at a GlanceMatti Krüger, Daniel Tanneberg, Chao Wang, Stephan Hasler, and Michael GiengerIn IEEE International Conference on Robot and Human Interactive Communication (RO-MAN), 2025The gaze of a person tends to reflect their interest. This work explores what happens when this statement is taken literally and applied to robots. Here we present a robot system that employs a moving robot head with a screen-based eye model that can direct the robot’s gaze to points in physical space and present a reflection-like mirror image of the attended region on top of each eye. We conducted a user study with 33 participants, who were asked to instruct the robot to perform pick-and-place tasks, monitor the robot’s task execution, and interrupt it in case of erroneous actions. Despite a deliberate lack of instructions about the role of the eyes and a very brief system exposure, participants felt more aware about the robot’s information processing, detected erroneous actions earlier, and rated the user experience higher when eye-based mirroring was enabled compared to non-reflective eyes. These results suggest a beneficial and intuitive utilization of the introduced method in cooperative human-robot interaction.
@inproceedings{krueger2025mirroreyes, author = {Kr\"{u}ger, Matti and Tanneberg, Daniel and Wang, Chao and Hasler, Stephan and Gienger, Michael}, title = {Mirror Eyes: Explainable Human-Robot Interaction at a Glance}, booktitle = {IEEE International Conference on Robot and Human Interactive Communication (RO-MAN)}, year = {2025}, } -
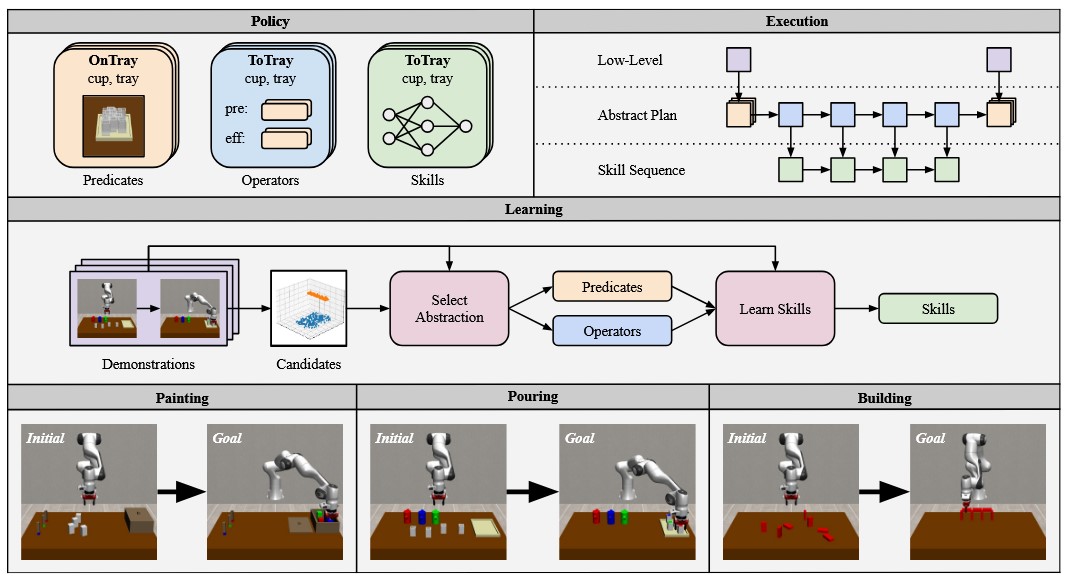 Neuro-Symbolic Imitation Learning: Discovering Symbolic Abstractions for Skill LearningLeon Keller, Daniel Tanneberg, and Jan PetersIn IEEE International Conference on Robotics and Automation (ICRA), 2025
Neuro-Symbolic Imitation Learning: Discovering Symbolic Abstractions for Skill LearningLeon Keller, Daniel Tanneberg, and Jan PetersIn IEEE International Conference on Robotics and Automation (ICRA), 2025Imitation learning is a popular method for teaching robots new behaviors. However, most existing methods focus on teaching short, isolated skills rather than long, multi-step tasks. To bridge this gap, imitation learning algorithms must not only learn individual skills but also an abstract understanding of how to sequence these skills to perform extended tasks effectively. This paper addresses this challenge by proposing a neuro-symbolic imitation learning framework. Using task demonstrations, the system first learns a symbolic representation that abstracts the low-level state-action space. The learned representation decomposes a task into easier subtasks and allows the system to leverage symbolic planning to generate abstract plans. Subsequently, the system utilizes this task decomposition to learn a set of neural skills capable of refining abstract plans into actionable robot commands. Experimental results in three simulated robotic environments demonstrate that, compared to baselines, our neuro-symbolic approach increases data efficiency, improves generalization capabilities, and facilitates interpretability.
@inproceedings{keller2025neuro, title = {Neuro-Symbolic Imitation Learning: Discovering Symbolic Abstractions for Skill Learning}, author = {Keller, Leon and Tanneberg, Daniel and Peters, Jan}, booktitle = {IEEE International Conference on Robotics and Automation (ICRA)}, year = {2025}, }
2024
-
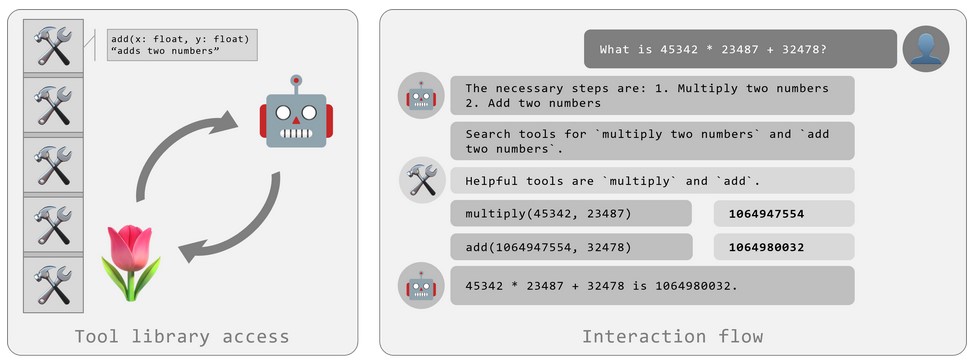 Tulip Agent–Enabling LLM-Based Agents to Solve Tasks Using Large Tool LibrariesFelix Ocker, Daniel Tanneberg, Julian Eggert, and Michael GiengerarXiv preprint arXiv:2407.21778, 2024
Tulip Agent–Enabling LLM-Based Agents to Solve Tasks Using Large Tool LibrariesFelix Ocker, Daniel Tanneberg, Julian Eggert, and Michael GiengerarXiv preprint arXiv:2407.21778, 2024We introduce tulip agent, an architecture for autonomous LLM-based agents with Create, Read, Update, and Delete access to a tool library containing a potentially large number of tools. In contrast to state-of-the-art implementations, tulip agent does not encode the descriptions of all available tools in the system prompt, which counts against the model’s context window, or embed the entire prompt for retrieving suitable tools. Instead, the tulip agent can recursively search for suitable tools in its extensible tool library, implemented exemplarily as a vector store. The tulip agent architecture significantly reduces inference costs, allows using even large tool libraries, and enables the agent to adapt and extend its set of tools. We evaluate the architecture with several ablation studies in a mathematics context and demonstrate its generalizability with an application to robotics.
@article{ocker2024tulip, title = {Tulip Agent--Enabling LLM-Based Agents to Solve Tasks Using Large Tool Libraries}, author = {Ocker, Felix and Tanneberg, Daniel and Eggert, Julian and Gienger, Michael}, journal = {arXiv preprint arXiv:2407.21778}, year = {2024}, } -
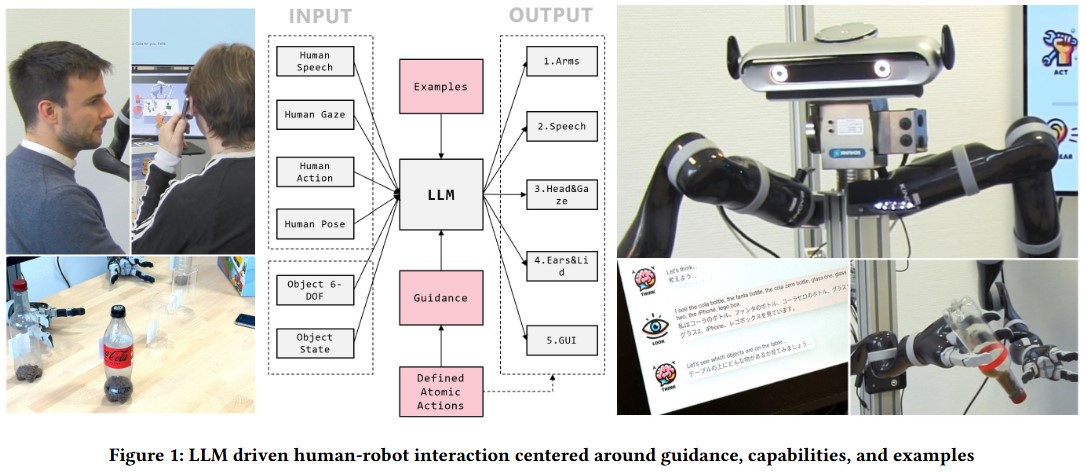 LaMI: Large language models for multi-modal human-robot interactionChao Wang, Stephan Hasler, Daniel Tanneberg, Felix Ocker, Frank Joublin, Antonello Ceravola, Joerg Deigmoeller, and Michael GiengerIn Extended Abstracts of the CHI Conference on Human Factors in Computing Systems, 2024
LaMI: Large language models for multi-modal human-robot interactionChao Wang, Stephan Hasler, Daniel Tanneberg, Felix Ocker, Frank Joublin, Antonello Ceravola, Joerg Deigmoeller, and Michael GiengerIn Extended Abstracts of the CHI Conference on Human Factors in Computing Systems, 2024This paper presents an innovative large language model (LLM)-based robotic system for enhancing multi-modal human-robot interaction (HRI). Traditional HRI systems relied on complex designs for intent estimation, reasoning, and behavior generation, which were resource-intensive. In contrast, our system empowers researchers and practitioners to regulate robot behavior through three key aspects: providing high-level linguistic guidance, creating "atomic actions" and expressions the robot can use, and offering a set of examples. Implemented on a physical robot, it demonstrates proficiency in adapting to multi-modal inputs and determining the appropriate manner of action to assist humans with its arms, following researchers’ defined guidelines. Simultaneously, it coordinates the robot’s lid, neck, and ear movements with speech output to produce dynamic, multi-modal expressions. This showcases the system’s potential to revolutionize HRI by shifting from conventional, manual state-and-flow design methods to an intuitive, guidance-based, and example-driven approach.
@inproceedings{wang2024lami, title = {LaMI: Large language models for multi-modal human-robot interaction}, author = {Wang, Chao and Hasler, Stephan and Tanneberg, Daniel and Ocker, Felix and Joublin, Frank and Ceravola, Antonello and Deigmoeller, Joerg and Gienger, Michael}, booktitle = {Extended Abstracts of the CHI Conference on Human Factors in Computing Systems}, year = {2024}, } -
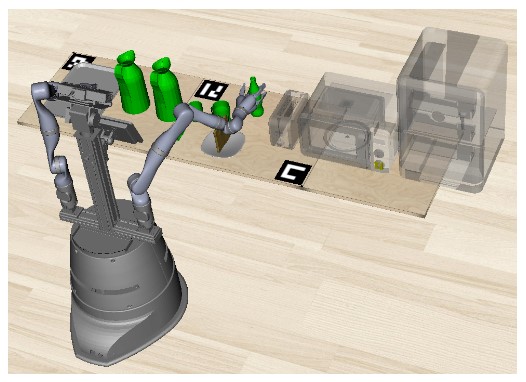 Efficient Symbolic Planning with ViewsStephan Hasler, Daniel Tanneberg, and Michael GiengerarXiv, 2024
Efficient Symbolic Planning with ViewsStephan Hasler, Daniel Tanneberg, and Michael GiengerarXiv, 2024Robotic planning systems model spatial relations in detail as these are needed for manipulation tasks. In contrast to this, other physical attributes of objects and the effect of devices are usually oversimplified and expressed by abstract compound attributes. This limits the ability of planners to find alternative solutions. We propose to break these compound attributes down into a shared set of elementary attributes. This strongly facilitates generalization between different tasks and environments and thus helps to find innovative solutions. On the down-side, this generalization comes with an increased complexity of the solution space. Therefore, as the main contribution of the paper, we propose a method that splits the planning problem into a sequence of views, where in each view only an increasing subset of attributes is considered. We show that this view-based strategy offers a good compromise between planning speed and quality of the found plan, and discuss its general applicability and limitations.
@article{hasler2024efficient, title = {Efficient Symbolic Planning with Views}, author = {Hasler, Stephan and Tanneberg, Daniel and Gienger, Michael}, journal = {arXiv}, year = {2024}, } -
 To Help or Not to Help: LLM-based Attentive Support for Human-Robot Group InteractionsDaniel Tanneberg, Felix Ocker, Stephan Hasler, Joerg Deigmoeller, Anna Belardinelli, Chao Wang, Heiko Wersing, Bernhard Sendhoff, and Michael GiengerIn IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024
To Help or Not to Help: LLM-based Attentive Support for Human-Robot Group InteractionsDaniel Tanneberg, Felix Ocker, Stephan Hasler, Joerg Deigmoeller, Anna Belardinelli, Chao Wang, Heiko Wersing, Bernhard Sendhoff, and Michael GiengerIn IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024How can a robot provide unobtrusive physical support within a group of humans? We present Attentive Support, a novel interaction concept for robots to support a group of humans. It combines scene perception, dialogue acquisition, situation understanding, and behavior generation with the common-sense reasoning capabilities of Large Language Models (LLMs). In addition to following user instructions, Attentive Support is capable of deciding when and how to support the humans, and when to remain silent to not disturb the group. With a diverse set of scenarios, we show and evaluate the robot’s attentive behavior, which supports and helps the humans when required, while not disturbing if no help is needed.
@inproceedings{tanneberg2024help, title = {To Help or Not to Help: LLM-based Attentive Support for Human-Robot Group Interactions}, author = {Tanneberg, Daniel and Ocker, Felix and Hasler, Stephan and Deigmoeller, Joerg and Belardinelli, Anna and Wang, Chao and Wersing, Heiko and Sendhoff, Bernhard and Gienger, Michael}, booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}, year = {2024}, } -
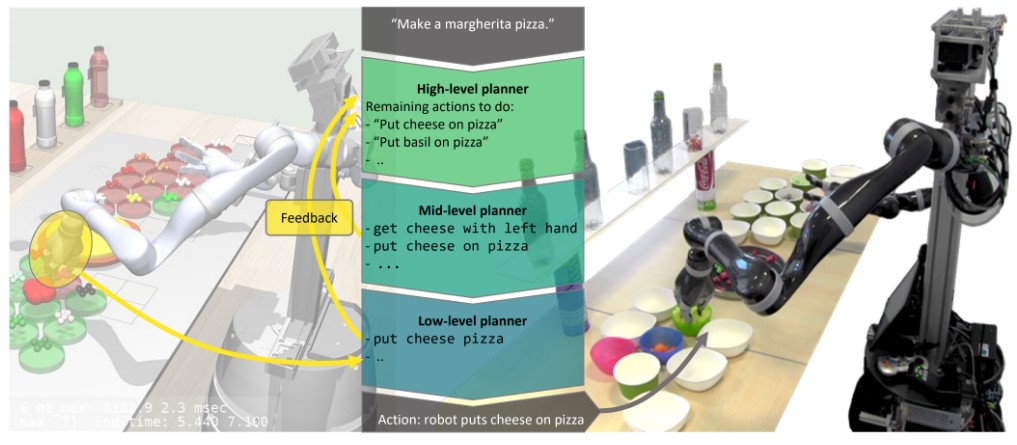 Copal: corrective planning of robot actions with large language modelsFrank Joublin, Antonello Ceravola, Pavel Smirnov, Felix Ocker, Joerg Deigmoeller, Anna Belardinelli, Chao Wang, Stephan Hasler, Daniel Tanneberg, and Michael GiengerIn IEEE International Conference on Robotics and Automation (ICRA), 2024
Copal: corrective planning of robot actions with large language modelsFrank Joublin, Antonello Ceravola, Pavel Smirnov, Felix Ocker, Joerg Deigmoeller, Anna Belardinelli, Chao Wang, Stephan Hasler, Daniel Tanneberg, and Michael GiengerIn IEEE International Conference on Robotics and Automation (ICRA), 2024In the pursuit of fully autonomous robotic systems capable of taking over tasks traditionally performed by humans, the complexity of open-world environments poses a considerable challenge. Addressing this imperative, this study contributes to the field of Large Language Models (LLMs) applied to task and motion planning for robots. We propose a system architecture that orchestrates a seamless interplay between multiple cognitive levels, encompassing reasoning, planning, and motion generation. At its core lies a novel replanning strategy that handles physically grounded, logical, and semantic errors in the generated plans. We demonstrate the efficacy of the proposed feedback architecture, particularly its impact on executability, correctness, and time complexity via empirical evaluation in the context of a simulation and two intricate real-world scenarios: blocks world, barman and pizza preparation.
@inproceedings{joublin2024copal, title = {Copal: corrective planning of robot actions with large language models}, author = {Joublin, Frank and Ceravola, Antonello and Smirnov, Pavel and Ocker, Felix and Deigmoeller, Joerg and Belardinelli, Anna and Wang, Chao and Hasler, Stephan and Tanneberg, Daniel and Gienger, Michael}, booktitle = {IEEE International Conference on Robotics and Automation (ICRA)}, year = {2024}, }
2023
-
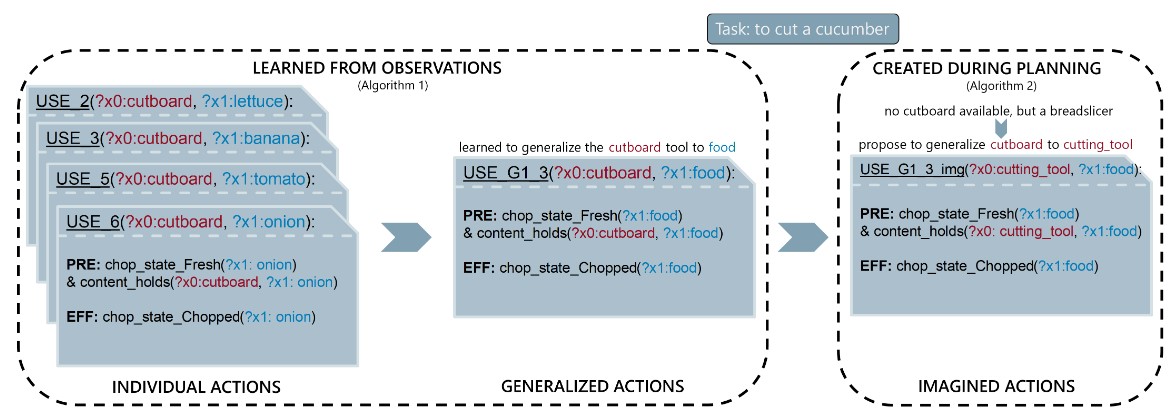 Learning type-generalized actions for symbolic planningDaniel Tanneberg and Michael GiengerIn IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2023
Learning type-generalized actions for symbolic planningDaniel Tanneberg and Michael GiengerIn IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2023Symbolic planning is a powerful technique to solve complex tasks that require long sequences of actions and can equip an intelligent agent with complex behavior. The downside of this approach is the necessity for suitable symbolic representations describing the state of the environment as well as the actions that can change it. Traditionally such representations are carefully hand-designed by experts for distinct problem domains, which limits their transferability to different problems and environment complexities. In this paper, we propose a novel concept to generalize symbolic actions using a given entity hierarchy and observed similar behavior. In a simulated grid-based kitchen environment, we show that type-generalized actions can be learned from few observations and generalize to novel situations. Incorporating an additional on-the-fly generalization mechanism during planning, unseen task combinations, involving longer sequences, novel entities and unexpected environment behavior, can be solved.
@inproceedings{tanneberg2023learning, title = {Learning type-generalized actions for symbolic planning}, author = {Tanneberg, Daniel and Gienger, Michael}, booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}, year = {2023}, } -
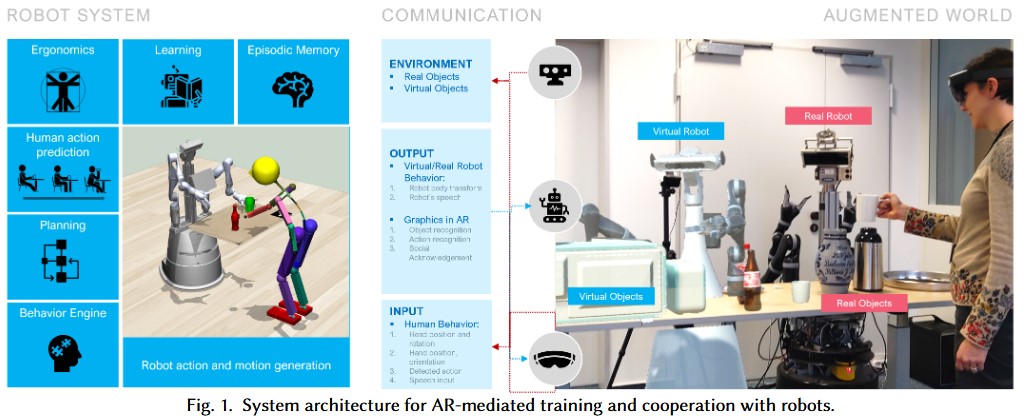 Explainable human-robot training and cooperation with augmented realityChao Wang, Anna Belardinelli, Stephan Hasler, Theodoros Stouraitis, Daniel Tanneberg, and Michael GiengerIn Extended Abstracts of the 2023 CHI Conference on Human Factors in Computing Systems, 2023
Explainable human-robot training and cooperation with augmented realityChao Wang, Anna Belardinelli, Stephan Hasler, Theodoros Stouraitis, Daniel Tanneberg, and Michael GiengerIn Extended Abstracts of the 2023 CHI Conference on Human Factors in Computing Systems, 2023The current spread of social and assistive robotics applications is increasingly highlighting the need for robots that can be easily taught and interacted with, even by users with no technical background. Still, it is often difficult to grasp what such robots know or to assess if a correct representation of the task is being formed. Augmented Reality (AR) has the potential to bridge this gap. We demonstrate three use cases where AR design elements enhance the explainability and efficiency of human-robot interaction: 1) a human teaching a robot some simple kitchen tasks by demonstration, 2) the robot showing its plan for solving novel tasks in AR to a human for validation, and 3) a robot communicating its intentions via AR while assisting people with limited mobility during daily activities.
@inproceedings{wang2023explainable, title = {Explainable human-robot training and cooperation with augmented reality}, author = {Wang, Chao and Belardinelli, Anna and Hasler, Stephan and Stouraitis, Theodoros and Tanneberg, Daniel and Gienger, Michael}, booktitle = {Extended Abstracts of the 2023 CHI Conference on Human Factors in Computing Systems}, year = {2023}, key = {https://arxiv.org/pdf/2302.01039} }
2022
-
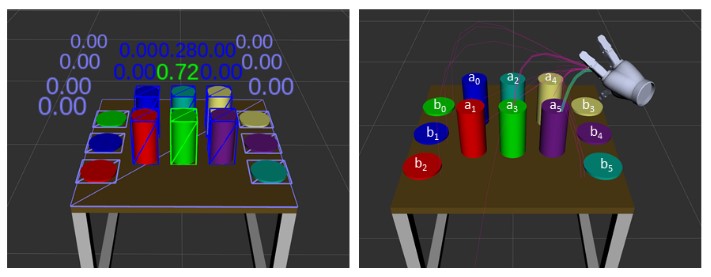 Intention estimation from gaze and motion features for human-robot shared-control object manipulationAnna Belardinelli, Anirudh Reddy Kondapally, Dirk Ruiken, Daniel Tanneberg, and Tomoki WatabeIn IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2022
Intention estimation from gaze and motion features for human-robot shared-control object manipulationAnna Belardinelli, Anirudh Reddy Kondapally, Dirk Ruiken, Daniel Tanneberg, and Tomoki WatabeIn IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2022Shared control can help in teleoperated object manipulation by assisting with the execution of the user’s intention. To this end, robust and prompt intention estimation is needed, which relies on behavioral observations. Here, an intention estimation framework is presented, which uses natural gaze and motion features to predict the current action and the target object. The system is trained and tested in a simulated environment with pick and place sequences produced in a relatively cluttered scene and with both hands, with possible hand-over to the other hand. Validation is conducted across different users and hands, achieving good accuracy and earliness of prediction. An analysis of the predictive power of single features shows the predominance of the grasping trigger and the gaze features in the early identification of the current action. In the current framework, the same probabilistic model can be used for the two hands working in parallel and independently, while a rule-based model is proposed to identify the resulting bimanual action. Finally, limitations and perspectives of this approach to more complex, full-bimanual manipulations are discussed.
@inproceedings{belardinelli2022intention, title = {Intention estimation from gaze and motion features for human-robot shared-control object manipulation}, author = {Belardinelli, Anna and Kondapally, Anirudh Reddy and Ruiken, Dirk and Tanneberg, Daniel and Watabe, Tomoki}, booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}, year = {2022}, }
2021
-
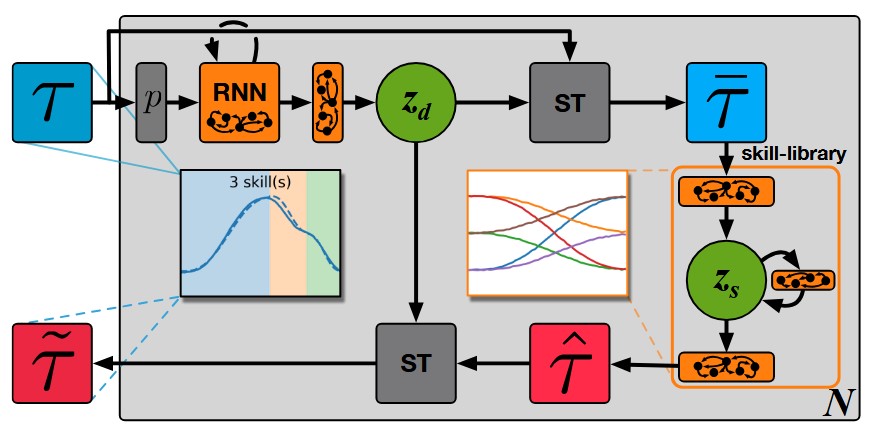 SKID RAW: Skill Discovery from Raw TrajectoriesDaniel Tanneberg, Kai Ploeger, Elmar Rueckert, and Jan PetersIEEE Robotics and Automation Letters, 2021
SKID RAW: Skill Discovery from Raw TrajectoriesDaniel Tanneberg, Kai Ploeger, Elmar Rueckert, and Jan PetersIEEE Robotics and Automation Letters, 2021Integrating robots in complex everyday environments requires a multitude of problems to be solved. One crucial feature among those is to equip robots with a mechanism for teaching them a new task in an easy and natural way. When teaching tasks that involve sequences of different skills, with varying order and number of these skills, it is desirable to only demonstrate full task executions instead of all individual skills. For this purpose, we propose a novel approach that simultaneously learns to segment trajectories into reoccurring patterns and the skills to reconstruct these patterns from unlabelled demonstrations without further supervision. Moreover, the approach learns a skill conditioning that can be used to understand possible sequences of skills, a practical mechanism to be used in, for example, human-robot-interactions for a more intelligent and adaptive robot behaviour. The Bayesian and variational inference based approach is evaluated on synthetic and real human demonstrations with varying complexities and dimensionality, showing the successful learning of segmentations and skill libraries from unlabelled data.
@article{tanneberg2021skid, title = {SKID RAW: Skill Discovery from Raw Trajectories}, author = {Tanneberg, Daniel and Ploeger, Kai and Rueckert, Elmar and Peters, Jan}, journal = {IEEE Robotics and Automation Letters}, year = {2021}, }
2020
-
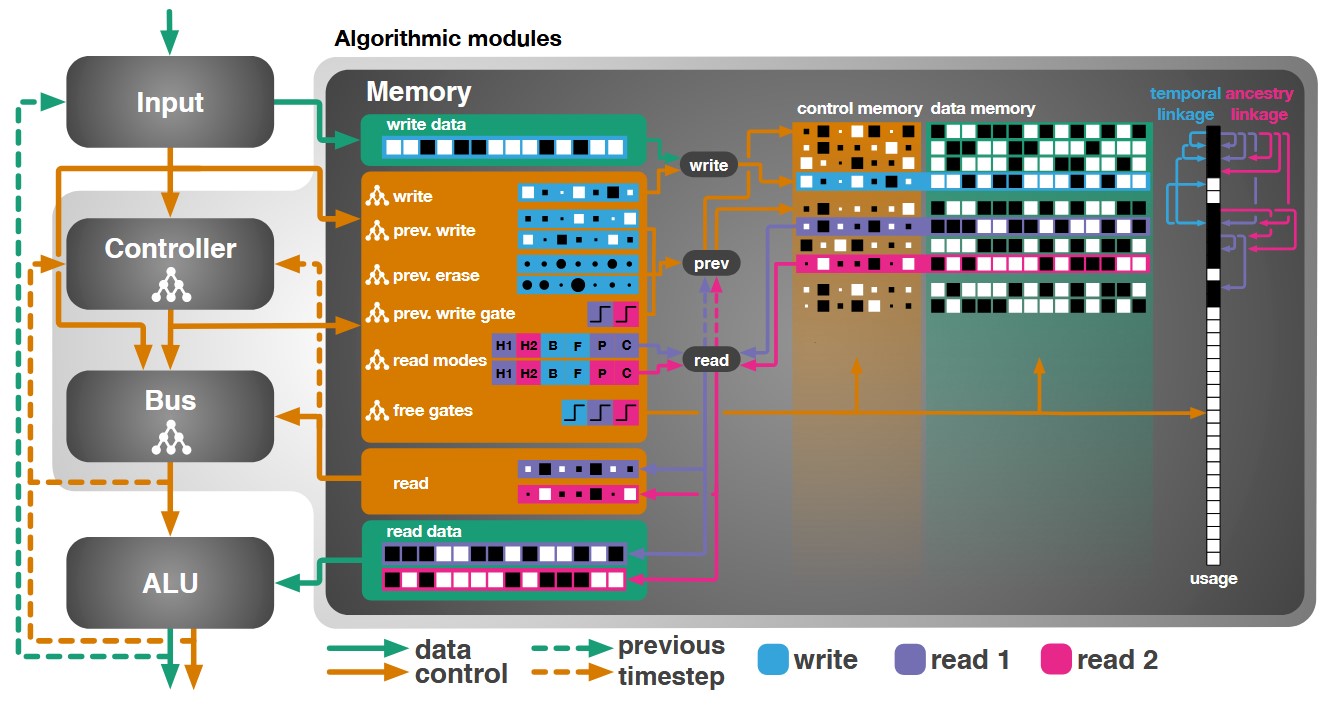 Evolutionary training and abstraction yields algorithmic generalization of neural computersDaniel Tanneberg, Elmar Rueckert, and Jan PetersNature Machine Intelligence, 2020
Evolutionary training and abstraction yields algorithmic generalization of neural computersDaniel Tanneberg, Elmar Rueckert, and Jan PetersNature Machine Intelligence, 2020A key feature of intelligent behaviour is the ability to learn abstract strategies that scale and transfer to unfamiliar problems. An abstract strategy solves every sample from a problem class, no matter its representation or complexity – like algorithms in computer science. Neural networks are powerful models for processing sensory data, discovering hidden patterns, and learning complex functions, but they struggle to learn such iterative, sequential or hierarchical algorithmic strategies. Extending neural networks with external memories has increased their capacities in learning such strategies, but they are still prone to data variations, struggle to learn scalable and transferable solutions, and require massive training data. We present the Neural Harvard Computer (NHC), a memory-augmented network based architecture, that employs abstraction by decoupling algorithmic operations from data manipulations, realized by splitting the information flow and separated modules. This abstraction mechanism and evolutionary training enable the learning of robust and scalable algorithmic solutions. On a diverse set of 11 algorithms with varying complexities, we show that the NHC reliably learns algorithmic solutions with strong generalization and abstraction: perfect generalization and scaling to arbitrary task configurations and complexities far beyond seen during training, and being independent of the data representation and the task domain.
@article{tanneberg2020evolutionary, title = {Evolutionary training and abstraction yields algorithmic generalization of neural computers}, author = {Tanneberg, Daniel and Rueckert, Elmar and Peters, Jan}, journal = {Nature Machine Intelligence}, year = {2020}, } -
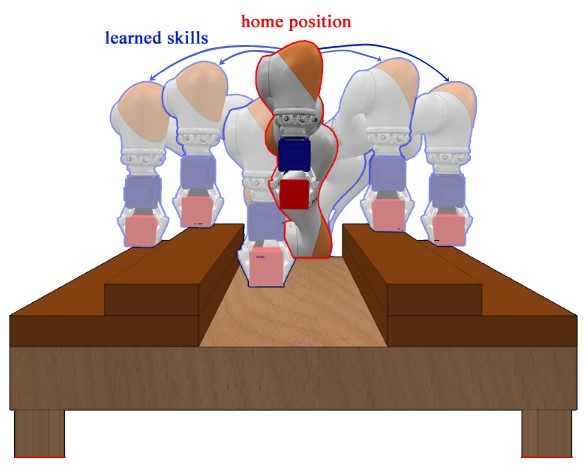 Model-Based Quality-Diversity Search for Efficient Robot LearningLeon Keller, Daniel Tanneberg, Svenja Stark, and Jan PetersIn IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2020
Model-Based Quality-Diversity Search for Efficient Robot LearningLeon Keller, Daniel Tanneberg, Svenja Stark, and Jan PetersIn IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2020Despite recent progress in robot learning, it still remains a challenge to program a robot to deal with open-ended object manipulation tasks. One approach that was recently used to autonomously generate a repertoire of diverse skills is a novelty based Quality-Diversity (QD) algorithm. However, as most evolutionary algorithms, QD suffers from sample-inefficiency and, thus, it is challenging to apply it in real-world scenarios. This paper tackles this problem by integrating a neural network that predicts the behavior of the perturbed parameters into a novelty based QD algorithm. In the proposed Model-based Quality-Diversity search (M-QD), the network is trained concurrently to the repertoire and is used to avoid executing unpromising actions in the novelty search process. Furthermore, it is used to adapt the skills of the final repertoire in order to generalize the skills to different scenarios. Our experiments show that enhancing a QD algorithm with such a forward model improves the sample-efficiency and performance of the evolutionary process and the skill adaptation.
@inproceedings{keller2020model, title = {Model-Based Quality-Diversity Search for Efficient Robot Learning}, author = {Keller, Leon and Tanneberg, Daniel and Stark, Svenja and Peters, Jan}, booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}, year = {2020}, }
2019
-
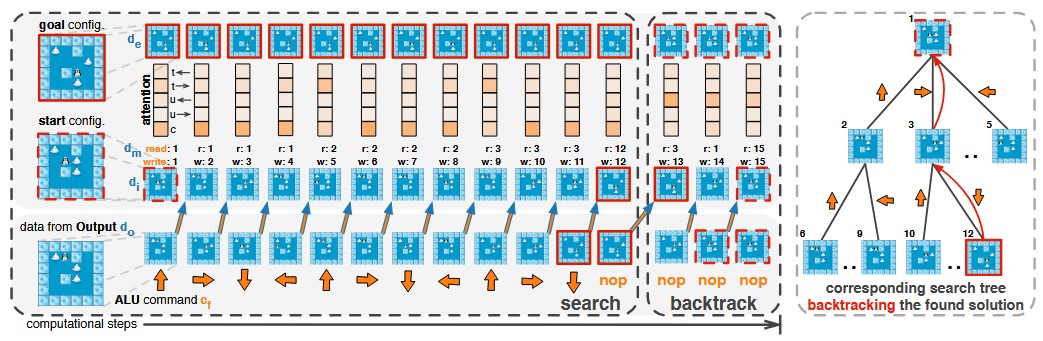 Learning Algorithmic Solutions to Symbolic Planning Tasks with a Neural Computer ArchitectureDaniel Tanneberg, Elmar Rueckert, and Jan PetersarXiv preprint arXiv:1911.00926, 2019
Learning Algorithmic Solutions to Symbolic Planning Tasks with a Neural Computer ArchitectureDaniel Tanneberg, Elmar Rueckert, and Jan PetersarXiv preprint arXiv:1911.00926, 2019A key feature of intelligent behavior is the ability to learn abstract strategies that transfer to unfamiliar problems. Therefore, we present a novel architecture, based on memory-augmented networks, that is inspired by the von Neumann and Harvard architectures of modern computers. This architecture enables the learning of abstract algorithmic solutions via Evolution Strategies in a reinforcement learning setting. Applied to Sokoban, sliding block puzzle and robotic manipulation tasks, we show that the architecture can learn algorithmic solutions with strong generalization and abstraction: scaling to arbitrary task configurations and complexities, and being independent of both the data representation and the task domain.
@article{tanneberg2019learning, title = {Learning Algorithmic Solutions to Symbolic Planning Tasks with a Neural Computer Architecture}, author = {Tanneberg, Daniel and Rueckert, Elmar and Peters, Jan}, journal = {arXiv preprint arXiv:1911.00926}, year = {2019}, } -
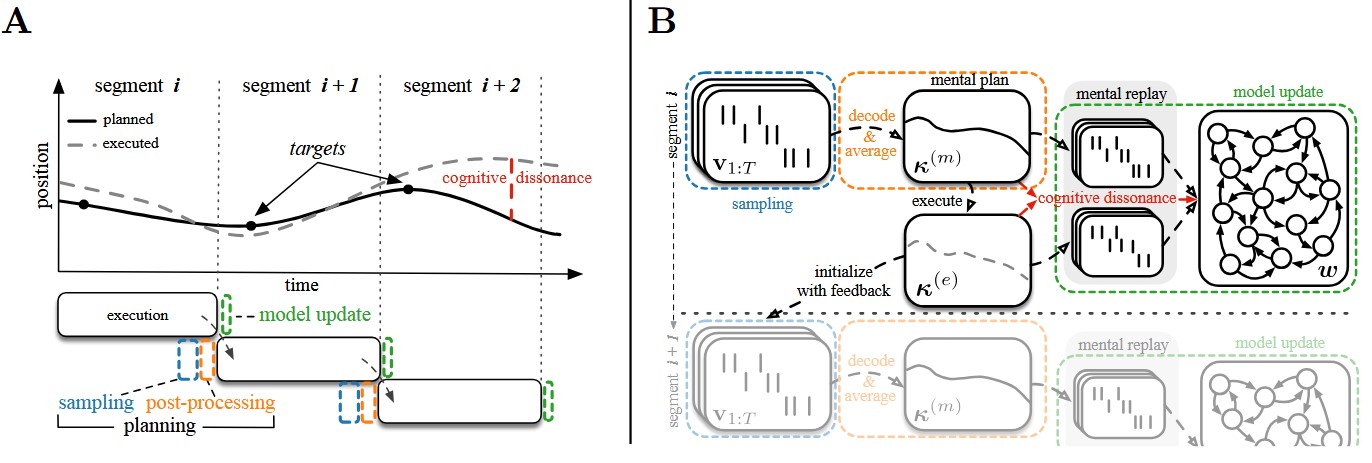 Intrinsic Motivation and Mental Replay enable Efficient Online Adaptation in Stochastic Recurrent NetworksDaniel Tanneberg, Jan Peters, and Elmar RueckertNeural Networks, 2019
Intrinsic Motivation and Mental Replay enable Efficient Online Adaptation in Stochastic Recurrent NetworksDaniel Tanneberg, Jan Peters, and Elmar RueckertNeural Networks, 2019Autonomous robots need to interact with unknown, unstructured and changing environments, constantly facing novel challenges. Therefore, continuous online adaptation for lifelong-learning and the need of sample-efficient mechanisms to adapt to changes in the environment, the constraints, the tasks, or the robot itself are crucial. In this work, we propose a novel framework for probabilistic online motion planning with online adaptation based on a bio-inspired stochastic recurrent neural network. By using learning signals which mimic the intrinsic motivation signalcognitive dissonance in addition with a mental replay strategy to intensify experiences, the stochastic recurrent network can learn from few physical interactions and adapts to novel environments in seconds. We evaluate our online planning and adaptation framework on an anthropomorphic KUKA LWR arm. The rapid online adaptation is shown by learning unknown workspace constraints sample-efficiently from few physical interactions while following given way points.
@article{tanneberg2019intrinsic, title = {Intrinsic Motivation and Mental Replay enable Efficient Online Adaptation in Stochastic Recurrent Networks}, author = {Tanneberg, Daniel and Peters, Jan and Rueckert, Elmar}, journal = {Neural Networks}, year = {2019}, }
2017
-
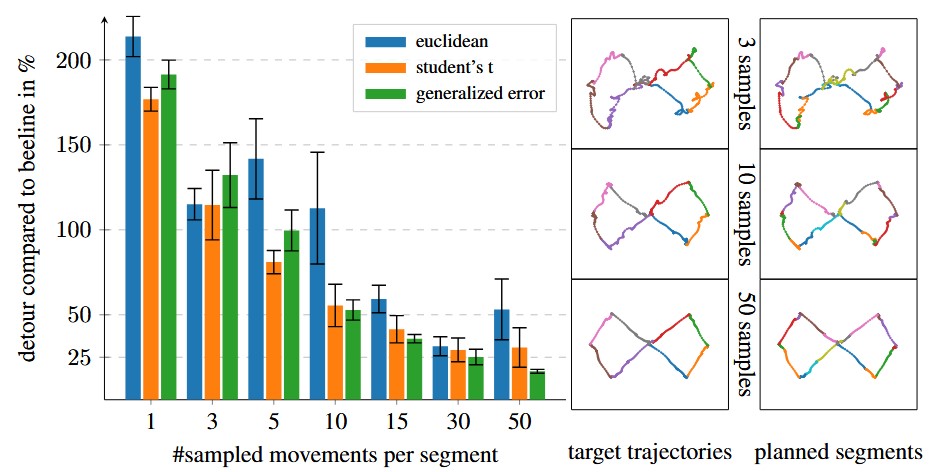 Online learning with stochastic recurrent neural networks using intrinsic motivation signalsDaniel Tanneberg, Jan Peters, and Elmar RueckertIn Conference on Robot Learning, 2017
Online learning with stochastic recurrent neural networks using intrinsic motivation signalsDaniel Tanneberg, Jan Peters, and Elmar RueckertIn Conference on Robot Learning, 2017Continuous online adaptation is an essential ability for the vision of fully autonomous and lifelong-learning robots. Robots need to be able to adapt to changing environments and constraints while this adaption should be performed without interrupting the robot’s motion. In this paper, we introduce a framework for probabilistic online motion planning and learning based on a bio-inspired stochastic recurrent neural network. Furthermore, we show that the model can adapt online and sample-efficiently using intrinsic motivation signals and a mental replay strategy. This fast adaptation behavior allows the robot to learn from only a small number of physical interactions and is a promising feature for reusing the model in different environments. We evaluate the online planning with a realistic dynamic simulation of the KUKA LWR robotic arm. The efficient online adaptation is shown in simulation by learning an unknown workspace constraint using mental replay and\textitcognitive dissonance as intrinsic motivation signal.
@inproceedings{tanneberg2017online, title = {Online learning with stochastic recurrent neural networks using intrinsic motivation signals}, author = {Tanneberg, Daniel and Peters, Jan and Rueckert, Elmar}, booktitle = {Conference on Robot Learning}, year = {2017}, } -
 Efficient Online Adaptation with Stochastic Recurrent Neural NetworksDaniel Tanneberg, Jan Peters, and Elmar RueckertIn IEEE-RAS International Conference on Humanoid Robotics (Humanoids), 2017
Efficient Online Adaptation with Stochastic Recurrent Neural NetworksDaniel Tanneberg, Jan Peters, and Elmar RueckertIn IEEE-RAS International Conference on Humanoid Robotics (Humanoids), 2017Autonomous robots need to interact with unknown and unstructured environments. For continuous online adaptation in lifelong learning scenarios, they need sample-efficient mechanisms to adapt to changing environments, constraints, tasks and capabilities. In this paper, we introduce a framework for online motion planning and adaptation based on a bio-inspired stochastic recurrent neural network. By using the intrinsic motivation signal cognitive dissonance with a mental replay strategy, the robot can learn from few physical interactions and can therefore adapt to novel environments in seconds. We evaluate our online planning and adaptation framework on a KUKA LWR arm. The efficient online adaptation is shown by learning unknown workspace constraints sample-efficient within few seconds while following given via points.
@inproceedings{tanneberg2017efficient, title = {Efficient Online Adaptation with Stochastic Recurrent Neural Networks}, author = {Tanneberg, Daniel and Peters, Jan and Rueckert, Elmar}, booktitle = {IEEE-RAS International Conference on Humanoid Robotics (Humanoids)}, year = {2017}, organization = {IEEE}, } -
 Generalized exploration in policy searchHerke Hoof, Daniel Tanneberg, and Jan PetersMachine Learning, 2017
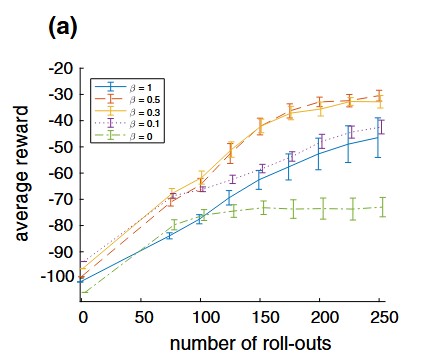
Generalized exploration in policy searchHerke Hoof, Daniel Tanneberg, and Jan PetersMachine Learning, 2017To learn control policies in unknown environments, learning agents need to explore by trying actions deemed suboptimal. In prior work, such exploration is performed by either perturbing the actions at each time-step independently, or by perturbing policy parameters over an entire episode. Since both of these strategies have certain advantages, a more balanced trade-off could be beneficial. We introduce a unifying view on step-based and episode-based exploration that allows for such balanced trade-offs. This trade-off strategy can be used with various reinforcement learning algorithms. In this paper, we study this generalized exploration strategy in a policy gradient method and in relative entropy policy search. We evaluate the exploration strategy on four dynamical systems and compare the results to the established step-based and episode-based exploration strategies. Our results show that a more balanced trade-off can yield faster learning and better final policies, and illustrate some of the effects that cause these performance differences.
@article{van2017generalized, title = {Generalized exploration in policy search}, author = {van Hoof, Herke and Tanneberg, Daniel and Peters, Jan}, journal = {Machine Learning}, year = {2017}, }
2016
-
 Deep spiking networks for model-based planning in humanoidsDaniel Tanneberg, Alexandres Paraschos, Jan Peters, and Elmar RueckertIn IEEE-RAS International Conference on Humanoid Robots (Humanoids), 2016
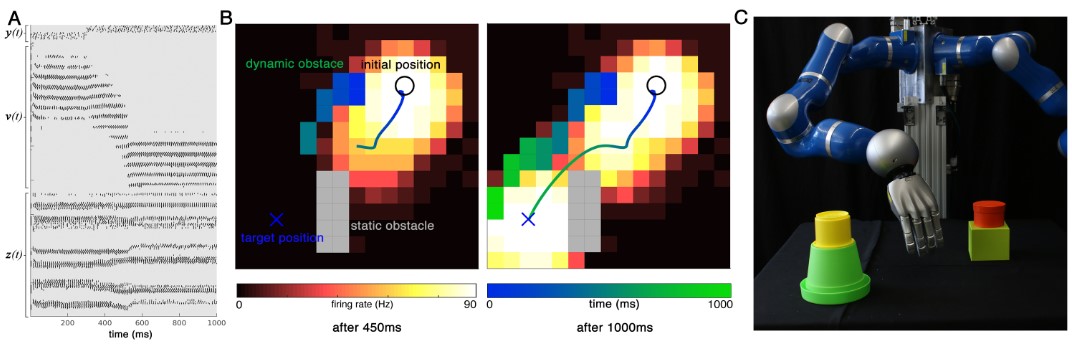
Deep spiking networks for model-based planning in humanoidsDaniel Tanneberg, Alexandres Paraschos, Jan Peters, and Elmar RueckertIn IEEE-RAS International Conference on Humanoid Robots (Humanoids), 2016We propose a novel bioinspired motion planning approach based on deep networks. This Deep Spiking Network (DSN) architecture couples task and joint space planning through bidirectional feedback. We show that the DSN can learn arbitrary complex functions, encode forward and inverse models, generate different solutions simultaneously and adapt dynamically to changing task constraints or environments. Furthermore, to scale to high-dimensional spaces, we introduce a factorized population coding in the model. Moreover, we show that the DSN can be trained efficiently and exclusively from human demonstrations to learn a task independent and reusable planning model. The model is evaluated in simulation and on two real high-dimensional humanoid robotic systems.
@inproceedings{tanneberg2016deep, title = {Deep spiking networks for model-based planning in humanoids}, author = {Tanneberg, Daniel and Paraschos, Alexandres and Peters, Jan and Rueckert, Elmar}, booktitle = {IEEE-RAS International Conference on Humanoid Robots (Humanoids)}, year = {2016}, } -
 Recurrent spiking networks solve planning tasksElmar Rueckert, David Kappel, Daniel Tanneberg, Dejan Pecevski, and Jan PetersScientific reports, 2016
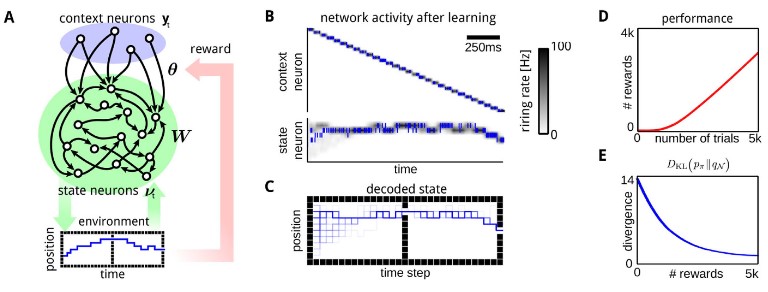
Recurrent spiking networks solve planning tasksElmar Rueckert, David Kappel, Daniel Tanneberg, Dejan Pecevski, and Jan PetersScientific reports, 2016A recurrent spiking neural network is proposed that implements planning as probabilistic inference for finite and infinite horizon tasks. The architecture splits this problem into two parts: The stochastic transient firing of the network embodies the dynamics of the planning task. With appropriate injected input this dynamics is shaped to generate high-reward state trajectories. A general class of reward-modulated plasticity rules for these afferent synapses is presented. The updates optimize the likelihood of getting a reward through a variant of an Expectation Maximization algorithm and learning is guaranteed to convergence to a local maximum. We find that the network dynamics are qualitatively similar to transient firing patterns during planning and foraging in the hippocampus of awake behaving rats. The model extends classical attractor models and provides a testable prediction on identifying modulating contextual information. In a real robot arm reaching and obstacle avoidance task the ability to represent multiple task solutions is investigated. The neural planning method with its local update rules provides the basis for future neuromorphic hardware implementations with promising potentials like large data processing abilities and early initiation of strategies to avoid dangerous situations in robot co-worker scenarios.
@article{rueckert2016recurrent, title = {Recurrent spiking networks solve planning tasks}, author = {Rueckert, Elmar and Kappel, David and Tanneberg, Daniel and Pecevski, Dejan and Peters, Jan}, journal = {Scientific reports}, year = {2016}, }