Mae govannen, mellon-nin! 🧙 My name is Daniel, and I am a Senior Scientist at the Honda Research Institute Europe. My research interest lies at the intersection of artificial intelligence 🧠, machine learning 🕹️, and robotics 🤖, with a focus on developing intelligent embodied agents that learn and adapt through interaction and experience.
Before joining Honda Research Institute Europe, I completed my Ph.D. in Computer Science 🎓 at the Technical University of Darmstadt in 2020. I conducted my doctoral research at the Intelligent Autonomous Systems Group, led by Prof. Jan Peters, and was co-supervised by Prof. Elmar Rueckert. My academic background also includes a Master of Science in Computer Science (with honors) in 2015, with a specialization in machine learning and robotics and a minor in biological psychology, as well as a Bachelor of Science in Computer Science in 2013 — both from the Technical University of Darmstadt.
Besides research and science 🧬🤖, I enjoy music 🎸, books 📚, (board) games 🎲🎮, and especially mountaineering 🏔️🧗.
Embodied Neurocomputation: A Framework for Interfacing Biological Neural Cultures with Scaled Task-Driven Validation
Johnson Zhou, Daniel Tanneberg, Forough Habibollahi, Alon Loeffler, Kiaran Lawson, Valentina Baccetti, Kwaku Dad Abu-Bonsrah, Candice Desouza, Finn Doensen, Bradley Watmuff, and others
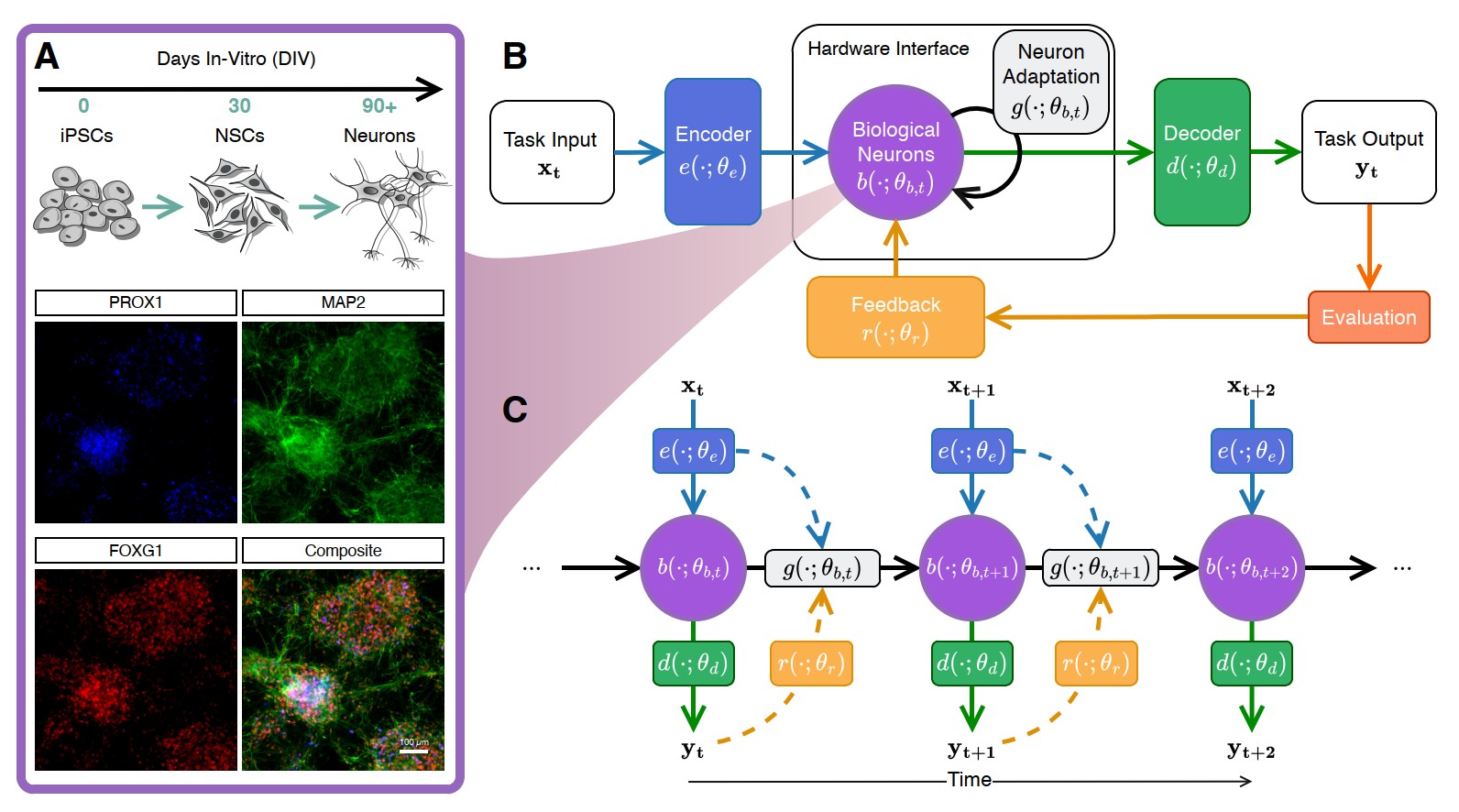
Biological neural networks (BNNs) have been established as a powerful and adaptive substrate that offer the potential for incredibly energy and data efficient information processing with distinct learning mechanisms. Yet a core challenge to utilizing BNN for neurocomputation is determining the optimal encoding and decoding mechanisms between the traditional silicon computing interface and the living biology. Here, we propose an Embodied Neurocomputation framework as a systems-level approach to this multi-variable optimization encoding/decoding problem. We operationalize this approach through the first large-scale parameter optimization of encoding configurations for a BNN agent performing closed-loop navigation along an odor-style gradient in a simulated grid-world. Despite the relative simplicity of the task, the biological interactions gave rise to a massive multi-combinatorial search space for optimal parameters. By considering how the components of the system are interconnected and parameterized, we evaluated approximately 1,300 parameter combinations, over 4,000 hours of real-time agent-environment interactions, to identify 12 configurations that consistently demonstrated learning across multiple episodes. These configurations achieved significantly higher task performances than optimized silicon-based DQN agents under the same interaction budget. These findings represent an initial step toward robust and scalable goal-oriented learning using BNNs. Our framework establishes a foundation for applying task-driven neurocomputing and supports the development of field-wide benchmarks. In the long term, this work supports the development of hybrid bio-silicon architectures capable of efficient, adaptive and real-time computation, including the potential for robotic control applications.
@article{zhou2026embodied,title={Embodied Neurocomputation: A Framework for Interfacing Biological Neural Cultures with Scaled Task-Driven Validation},author={Zhou, Johnson and Tanneberg, Daniel and Habibollahi, Forough and Loeffler, Alon and Lawson, Kiaran and Baccetti, Valentina and Abu-Bonsrah, Kwaku Dad and Desouza, Candice and Doensen, Finn and Watmuff, Bradley and others},journal={arXiv preprint arXiv:2605.13315},year={2026},}
Local Pairwise Distance Matching for Backpropagation-Free Reinforcement Learning
Daniel Tanneberg
In European Conference on Artificial Intelligence (ECAI), 2025
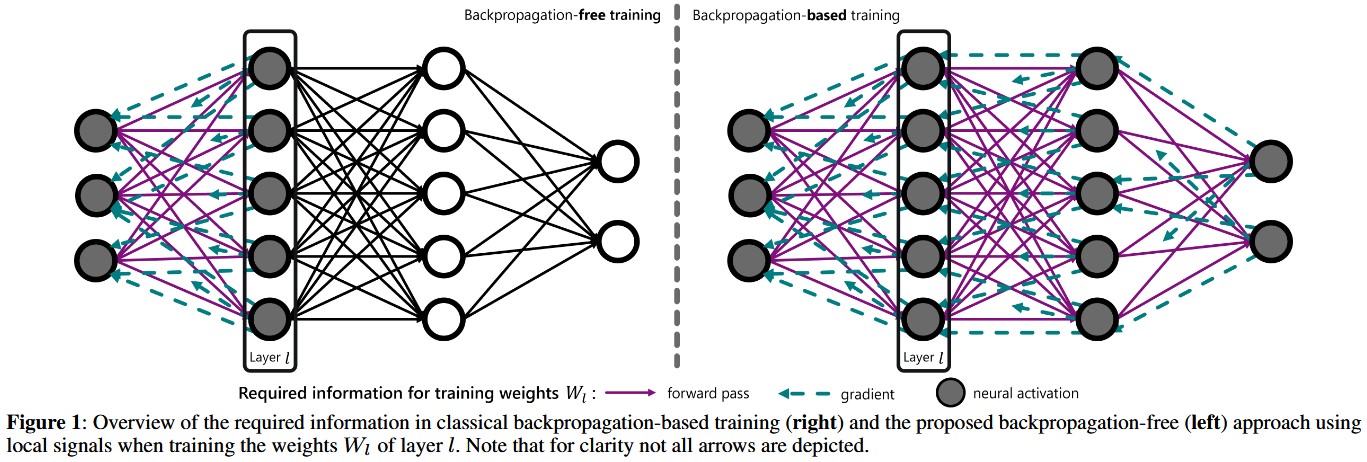
Training neural networks with reinforcement learning (RL) typically relies on backpropagation (BP), necessitating storage of activations from the forward pass for subsequent backward updates. Furthermore, backpropagating error signals through multiple layers often leads to vanishing or exploding gradients, which can degrade learning performance and stability. We propose a novel approach that trains each layer of the neural network using local signals during the forward pass in RL settings. Our approach introduces local, layer-wise losses leveraging the principle of matching pairwise distances from multi-dimensional scaling, enhanced with optional reward-driven guidance. This method allows each hidden layer to be trained using local signals computed during forward propagation, thus eliminating the need for backward passes and storing intermediate activations. Our experiments, conducted with policy gradient methods across common RL benchmarks, demonstrate that this backpropagation-free method achieves competitive performance compared to their classical BP-based counterpart. Additionally, the proposed method enhances stability and consistency within and across runs, and improves performance especially in challenging environments.
@inproceedings{tanneberg2025local,author={Tanneberg, Daniel},title={Local Pairwise Distance Matching for Backpropagation-Free Reinforcement Learning},booktitle={European Conference on Artificial Intelligence (ECAI)},year={2025},}
Neuro-Symbolic Imitation Learning: Discovering Symbolic Abstractions for Skill Learning
Leon Keller, Daniel Tanneberg, and Jan Peters
In IEEE International Conference on Robotics and Automation (ICRA), 2025
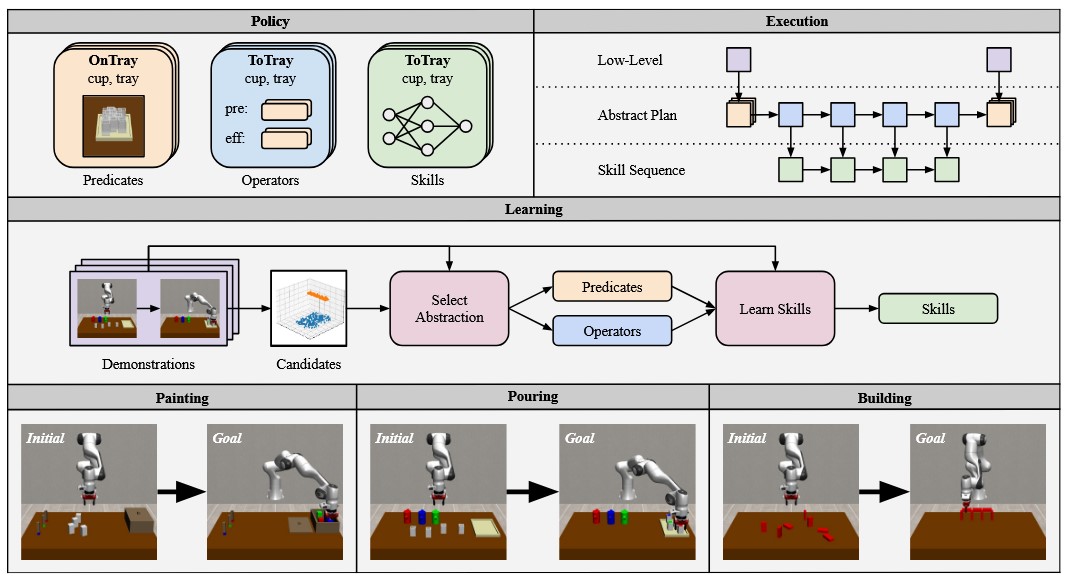
Imitation learning is a popular method for teaching robots new behaviors. However, most existing methods focus on teaching short, isolated skills rather than long, multi-step tasks. To bridge this gap, imitation learning algorithms must not only learn individual skills but also an abstract understanding of how to sequence these skills to perform extended tasks effectively. This paper addresses this challenge by proposing a neuro-symbolic imitation learning framework. Using task demonstrations, the system first learns a symbolic representation that abstracts the low-level state-action space. The learned representation decomposes a task into easier subtasks and allows the system to leverage symbolic planning to generate abstract plans. Subsequently, the system utilizes this task decomposition to learn a set of neural skills capable of refining abstract plans into actionable robot commands. Experimental results in three simulated robotic environments demonstrate that, compared to baselines, our neuro-symbolic approach increases data efficiency, improves generalization capabilities, and facilitates interpretability.
@inproceedings{keller2025neuro,title={Neuro-Symbolic Imitation Learning: Discovering Symbolic Abstractions for Skill Learning},author={Keller, Leon and Tanneberg, Daniel and Peters, Jan},booktitle={IEEE International Conference on Robotics and Automation (ICRA)},year={2025},}
SKID RAW: Skill Discovery from Raw Trajectories
Daniel Tanneberg, Kai Ploeger, Elmar Rueckert, and Jan Peters
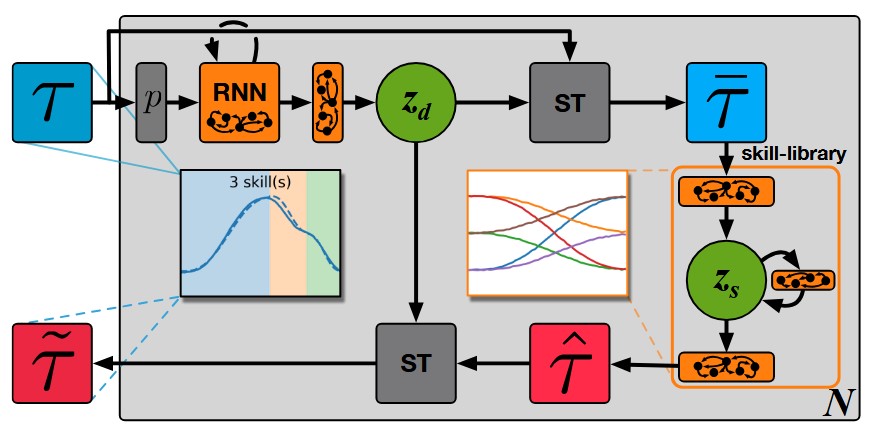
Integrating robots in complex everyday environments requires a multitude of problems to be solved. One crucial feature among those is to equip robots with a mechanism for teaching them a new task in an easy and natural way. When teaching tasks that involve sequences of different skills, with varying order and number of these skills, it is desirable to only demonstrate full task executions instead of all individual skills. For this purpose, we propose a novel approach that simultaneously learns to segment trajectories into reoccurring patterns and the skills to reconstruct these patterns from unlabelled demonstrations without further supervision. Moreover, the approach learns a skill conditioning that can be used to understand possible sequences of skills, a practical mechanism to be used in, for example, human-robot-interactions for a more intelligent and adaptive robot behaviour. The Bayesian and variational inference based approach is evaluated on synthetic and real human demonstrations with varying complexities and dimensionality, showing the successful learning of segmentations and skill libraries from unlabelled data.
@article{tanneberg2021skid,title={SKID RAW: Skill Discovery from Raw Trajectories},author={Tanneberg, Daniel and Ploeger, Kai and Rueckert, Elmar and Peters, Jan},journal={IEEE Robotics and Automation Letters},year={2021},}
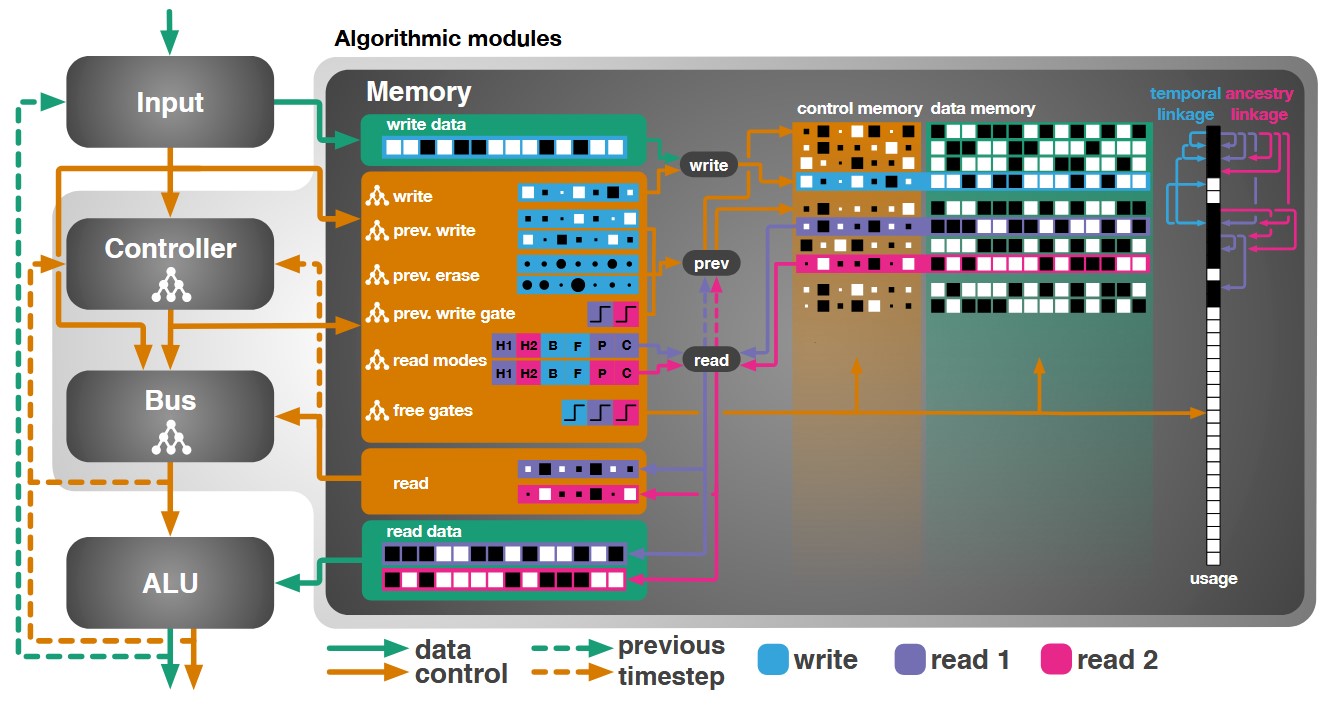
Evolutionary training and abstraction yields algorithmic generalization of neural computers
A key feature of intelligent behaviour is the ability to learn abstract strategies that scale and transfer to unfamiliar problems. An abstract strategy solves every sample from a problem class, no matter its representation or complexity – like algorithms in computer science. Neural networks are powerful models for processing sensory data, discovering hidden patterns, and learning complex functions, but they struggle to learn such iterative, sequential or hierarchical algorithmic strategies. Extending neural networks with external memories has increased their capacities in learning such strategies, but they are still prone to data variations, struggle to learn scalable and transferable solutions, and require massive training data. We present the Neural Harvard Computer (NHC), a memory-augmented network based architecture, that employs abstraction by decoupling algorithmic operations from data manipulations, realized by splitting the information flow and separated modules. This abstraction mechanism and evolutionary training enable the learning of robust and scalable algorithmic solutions. On a diverse set of 11 algorithms with varying complexities, we show that the NHC reliably learns algorithmic solutions with strong generalization and abstraction: perfect generalization and scaling to arbitrary task configurations and complexities far beyond seen during training, and being independent of the data representation and the task domain.
@article{tanneberg2020evolutionary,title={Evolutionary training and abstraction yields algorithmic generalization of neural computers},author={Tanneberg, Daniel and Rueckert, Elmar and Peters, Jan},journal={Nature Machine Intelligence},year={2020},}